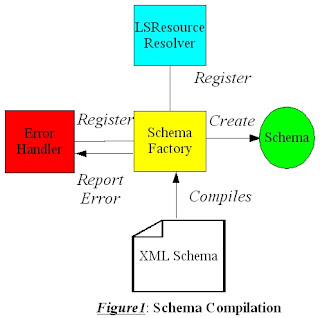
What is Google Webmaster Tools?

Google Search Console (previously Google Webmaster Tools) is a no-charge web service by Google for webmasters. It allows webmasters to check indexing status and optimize visibility of their websites. As of May 20, 2015, Google re-branded Google Webmaster Tools as Google Search Console. And the best part? It’s absolutely free. If you don’t have a GWT account, then you need to go get one now. This guide to Google Webmaster Tools will walk you through the various features of this tool, and give you insight into what actionable data can be found within. (For more in-depth help, go to Google’s Webmaster Help.) Verification Before you can access any data on your site, you have to prove that you’re an authorized representative of the site. This is done through a process of verification. There are five main methods of verification currently in place for GWT. There’s no real preference as to which method you use, although the first two tend to be the most commonly used as they’ve